引子
我不会Rust。
准确地说,我熟悉C/C++和Python,对Rust只有一些学院派的了解:知道它的所有权模型、知道它强调内存安全、知道它的编译器以”严格”著称。但要我自己从零写一个Rust项目,我写不出来。
然而最近我在给自己的机器人项目写驱动时,我选择了让AI用Rust来写。
更奇怪的是,我发现自己反而比让AI写Python时更放心。
过去一年多我一直用AI协作写Python。Python我很熟,熟到可以逐行审阅AI的代码。但正是这种熟悉让我焦虑,我太清楚Python有多少种方式可以让错误静默地溜走。
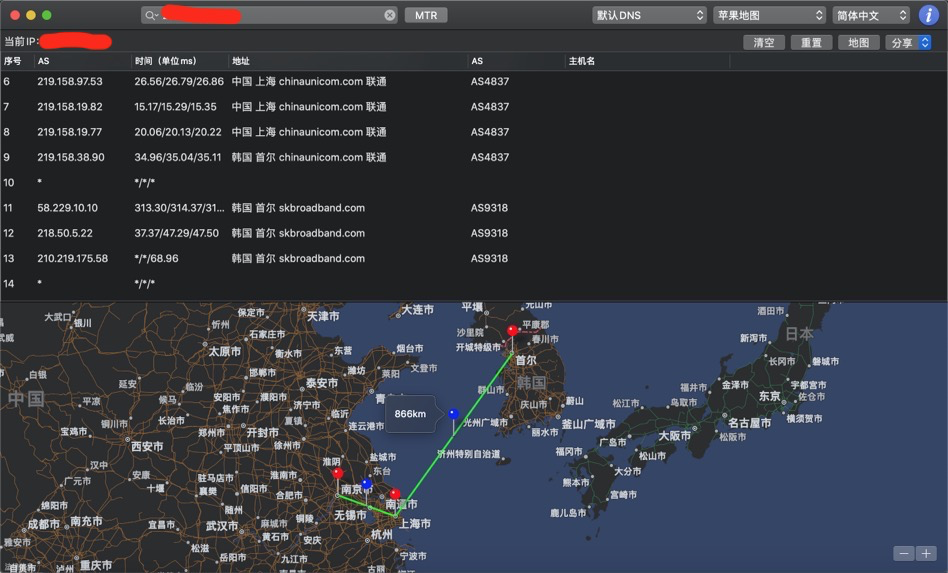
有一次我辛辛苦苦采集了大量机器人示教数据,后处理时发现数据有些地方很不一致。查了很久,最后发现是采集程序里AI写了一个 except: pass。在高频循环里,某些异常被静默吞掉了,程序继续跑,数据继续存,但有些帧的数据已经是错的。
这种错误让人恼火的程度远超一般的bug。如果我没发现呢?我可能会基于这批数据训练模型、做分析、得出结论,整个研究假设都建立在一个错误的基础上。这让我开始根本性地怀疑AI编程,有时候宁愿自己上手干。
而Rust?我看不懂它的每一行语法,但我知道,如果编译通过了,至少有一大类错误已经被排除在外。
当然,Rust不是银弹。它能拦住的是内存安全、类型匹配这类形式上的错误,拦不住逻辑本身就是错的。但这段体验让我开始思考一个问题:在人和AI协作编程时,”约束”这件事到底扮演什么角色?为什么有些约束让AI更可靠,而有些问题再多约束也没用?
AI的讨好倾向
那个 except: pass是怎么来的?
不是AI故意害我。恰恰相反,它是在努力让程序”能跑起来”。
这种倾向有它的来源。当前大模型的后训练过程,尤其是强化学习阶段,奖励函数的设计往往围绕着”单元测试通过”、”代码能运行”这类信号。这种训练方式确实带来了模型能力的显著提升,AI写的代码越来越能跑通了。但它也带来了一个副作用:模型学会了”让代码跑起来”这个目标,而不是”让代码正确”。
于是当AI遇到一个可能抛异常的地方,最省事的做法就是把异常吞掉。程序跑通了,测试过了,奖励拿到了。直到你发现数据是坏的。
Python允许这种”讨好”。语法上,except: pass完全合法。运行时,程序确实不崩。这个错误会安静地躺在代码里,等着在未来某个意想不到的时刻给你一击。
当然,这种”讨好”的危害程度因场景而异。如果你在写前端界面,AI吞掉了一个错误,结果可能是页面上缺了一块东西,你一眼就能看出来,改掉就是了,不致命。但科研场景不一样。数据采集、模型训练、结果分析,这些环节的错误往往是隐蔽的,不会立刻跳出来告诉你”这里错了”。你可能基于错误的数据得出了结论,写进了论文,直到很久以后才发现,或者永远发现不了。
我有段时间就在”用AI”和”不用AI”之间反复摇摆,不断思考这种协作模式对科研到底有没有用。直到我开始意识到,问题不在于”该不该用AI”,而在于”什么样的环境能让AI少犯这种错”。
这就是问题的根源:AI被训练出的优化目标,与宽松语言的包容性形成了危险的共振。 而在反馈不及时、错误不显眼的场景下,这种共振的后果尤其严重。
约束的本质:内化还是外化
说到这里,可能有人会觉得这只是”AI的问题”,等模型能力再强一些、训练方式再改进一些,问题自然就解决了。
但我想说的是,约束这件事,对所有认知主体都有用,不只是AI。
一个资深程序员可以用记事本写代码,不需要IDE,不需要lint,不需要静态检查。他脑子里装着几十年的经验:什么写法容易出bug、什么地方要做防御、什么模式会埋坑。这些规则他都记得,靠自律就能写出正确的代码。
但这种”内化的约束”是有代价的。它占用认知资源,依赖过去大量的工程实践,而且会疲劳、会遗忘、会在状态不好的时候放水。更关键的是,它不可迁移,他的经验没法复制给新人,也没法复制给AI。
而把这些规则外化给工具呢?IDE的自动补全、lint的风格检查、类型系统的静态分析、编译器的错误拦截,它们不疲劳、不遗忘、不放水。你想犯某些错误,它根本不让你犯。
这里面有一个关键变量:反馈的时机。
有些约束在你写代码时就生效,编辑器立刻标红;有些在编译时拦住你,不通过就没法继续;有些要到运行时才暴露,跑到那一行才报错;还有些更隐蔽,程序跑完了、结果出来了,你才慢慢发现哪里不对。
反馈越早、越确定,纠错成本就越低。反馈越晚、越模糊,错误就越容易累积、越难定位。
对AI来说,这个规律更加极端。AI没有”经验”可言,它无法内化规则,完全依赖外部信号来判断自己对不对。反馈回路越紧、越明确,它就越容易在这个空间里找到正确解;反馈越延迟、越模糊,它就越容易在”看起来对”的路上越走越远。
所以问题不是”该用什么语言”,而是:你的工作流里,有多少约束是外化的、反馈是及时的?
这让我意识到一个更普遍的道理:认知负担外化到确定性系统中,是一种普遍有效的策略。AI只是把这个规律展现得更极端,因为它完全没有内化能力,只能依赖外部约束。
设计层的约束:状态机的故事
前面说的主要是语言和工具层面的约束,编译器、类型系统、lint。但还有另一个层面同样重要:设计层的约束。
我有一个很痛的教训。
当时我在给Lerobot的遥操作程序适配自己的机械臂。这个采集流程看起来不复杂:开始时机械臂移动到工作姿态,等用户检查夹爪、扶稳示教臂,然后进入录制,记录轨迹和相机数据。用户按Enter开始采集,按S保存,按Backspace丢弃。
我把这些需求告诉AI,它很快写出了代码,看起来功能都实现了。
然后问题来了。
我多按了一下Enter,程序出问题了。我在初始状态按了S,机械臂居然开始保存。我按完S又按Backspace,数据丢了但程序不知道,episode序号乱了。同时按两下S呢?同时按两下Backspace呢?在非采集状态按这些键呢?
每一种我习惯性的操作都可能触发某个未定义行为。
AI写的代码在”正常流程”下是对的,但它只考虑了局部分支。现实中用户的按键是不可预测的,各种组合构成了一个巨大的状态空间,而AI只覆盖了其中很小一部分。剩下的,要么是程序崩溃,要么是更糟糕的,静默地做了错误的事。
我当时的debug方式是:发现问题、告诉AI、等它改、再测试、发现新问题、再告诉AI……这个循环可以无限持续下去。而且AI的修复方式往往是不断加if分支、加fallback,代码越来越像一团意大利面,改了A坏了B,改了B坏了A。
直到我意识到,问题根本不在代码层面,而在设计层面。
这种复杂交互场景需要的是一个状态机。每个状态下只有特定的输入是合法的,状态之间的转移是确定的,非法输入要么被忽略要么给出明确反馈。一旦这张图画出来,每个状态该做什么、能接受什么、转移到哪,都是清晰的。
于是我改变了策略:不直接让AI写代码,而是先让它帮我设计状态机。我们在文档层面反复迭代,有哪些状态、转移条件是什么、每个状态的合法输入有哪些。等这个顶层设计稳定了,再让AI照着写代码。
结果是:代码一次成型,所有的边界情况都被处理了。
这件事让我理解了一个道理:约束不只存在于语言和工具层面,更存在于设计层面。 状态机是一种约束,它强迫你穷举所有状态和转移,不给”未定义行为”留空间。而如果你不在设计层引入这种约束,直接让AI写代码,它就会在那个巨大的组合空间里乱撞,靠打补丁来应付问题。
当然,状态机只是这个场景下的解法。不同场景需要不同的高层思维模型:可能是管道模式、事件驱动、实体组件系统,或者别的什么。关键是,你得在动手写代码之前,先把这个模型立起来,让它成为AI工作的框架。
人机协作的新分工
回头看这一年多的协作经历,我发现自己做的事情在慢慢变化。
一开始我什么都审。AI写的每一行代码我都会看,每一个函数都要理解,每一个逻辑分支都要验证。这很累,但我觉得这是”负责任”的做法,毕竟代码是AI写的,我得确保它是对的。
但随着AI能力的进步,我逐渐发现这种审法不可持续。
不是因为我偷懒,是因为投入产出比不对。AI生成代码的速度远超人类阅读代码的速度。我十岁开始编程,对代码的阅读速度和掌握程度已经远超常人,但在AI廉价的代码量面前,逐行审阅变成了一种低效的消耗。
更让人恼火的是AI的工作方式。它写代码没有”最小改动”意识。你让它加两行功能,它会把整个文件吞进去再吐出来,然后你看到一堆琐碎的diff:这个变量本来叫 big_model它改叫 big_models,这个注释措辞变了,这里缩进调了。这些对它来说是无意识的行为,但对审阅者来说是巨大的噪音。你只想确认那两行改动对不对,结果上百个变化跳出来让你分辨。
于是我开始调整策略,把注意力往上游转移。
我发现了一个杠杆效应:一行坏的计划,会带来上百行坏的代码。 反过来说,如果计划是对的,代码层面的小错AI自己能修,编译器能拦住,测试能暴露。但如果计划就是错的,方向错了、架构选错了、模块划分不合理,那后面写再多代码都是在错误的路上狂奔。
所以现在我的工作流变成了这样:
在高层,我关注架构和设计。技术选型是我定的,整体思路是我想的,这些AI可以给建议,但最终决定是我做。
在中层,我关注模块划分和接口设计。为了实现某个复杂功能,应该拆成哪些模块、模块之间怎么通信、用什么样的抽象。这个层面我会先让AI写设计文档,我们反复讨论迭代,直到我觉得这个方案是solid的。
在底层,具体代码怎么写,我管得越来越少。语法细节、API调用、具体实现,这些AI来写,编译器来检查,测试来验证。有时候我甚至会给AI写伪代码,告诉它逻辑是什么,让它翻译成具体的语言。
人守上游,AI冲下游。 上游的错误代价极高,需要人来把关;下游的工作量大但纠错成本低,适合AI来做。这和传统的软件工程分工其实是一个道理,架构师定方向,工程师写实现,只不过现在”工程师”的角色有一部分被AI接管了。
约束的边界,与人应该守住的东西
前面讲的约束,不管是编译器层面还是设计层面,都有一个共同特点:它们能拦住的是形式上的错误。类型不匹配、内存不安全、状态转移不合法,这些都是可以被规则穷举、被系统检查的。
但有一类错误,再强的约束系统也拦不住。
我曾经花了两周时间debug一个问题。训练好的算法部署到机械臂上,机械臂总是砸桌子。但我离线测试的时候,每一步的轨迹趋势看起来都是正常的。这很奇怪。
最后发现,错误只是一行代码的位置:一个变量赋值应该在第49行而不是第51行。
我用的是相对轨迹运动模式,在一次rollout中,所有后续点都以起始pose作为参考起点。所以这个参考起点的设置应该在循环外侧,而不是内侧。放在内侧的话,参考点每一步都在变,轨迹就完全乱了。
这种错误,AI写的时候是不可能意识到的。它不知道真实世界里机械臂是怎么运动的,不知道”相对轨迹”意味着什么,不知道放错位置会导致什么后果。在它看来,第49行和第51行,语法都对,类型都对,程序都能跑。Rust也好,再严格的编译器也好,查不出这种错。
这就是约束系统的边界:它能保证形式正确性,但保证不了语义正确性。语义正确性的判断,需要理解代码背后的意图,理解它要解决的现实问题,理解物理世界的规律。
这让我开始想一个更根本的问题:在人和AI的协作中,到底什么是人必须守住的?
不妨做一个思想实验。假设AI能力继续发展,假设它学会了所有的设计模式和架构经验,假设有一天具身智能突破了,它也有了对物理世界的感知。那时候,人还剩下什么是不可替代的?
你可以换一个方式来想这件事:想象一个愿意帮助你、能力和知识都比你强很多的人。你想让他帮你完成一件事,什么是他帮不了你的?
答案可能很简单:你要什么。
需求得你来提。至少初始方向是你给的,哪怕在过程中会迭代和修正。
验收得你来判。对不对、好不好、够不够,这个标准在你那里。
过程中的方向调整得你来做。发现偏了、想法变了、优先级调了,这些信号只有你能发出。
这不是因为AI笨或者有局限,而是因为”协作”这件事本身的结构就是这样。有委托方,有执行方。委托方的这几件事,在结构上就是不可转移的。
AI越强,这件事反而越重要。因为执行不再是瓶颈,瓶颈变成了你能不能把需求想清楚、说清楚。过去我们花大量时间在”怎么实现”上,现在这部分可以外包了,但”实现什么”这个问题被推到了前台。
所以AI时代需要培养的意识可能是:更清晰地知道自己要什么,更敏锐地判断产出对不对,更主动地在过程中给出方向。这些能力过去被”我还得自己动手实现”这件事遮蔽了,现在遮蔽物被拿掉了,它们就显得格外重要。
这大概就是人应该守住的东西。